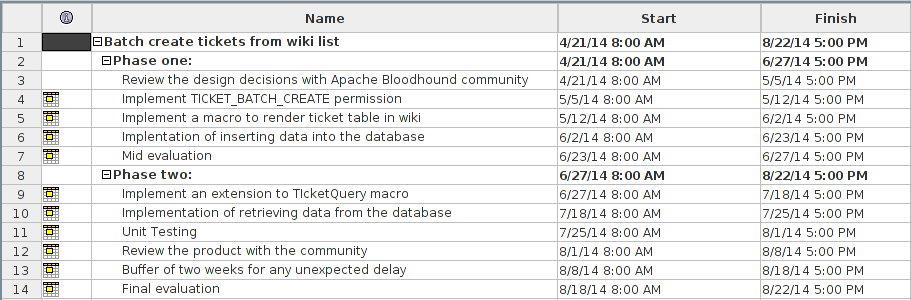
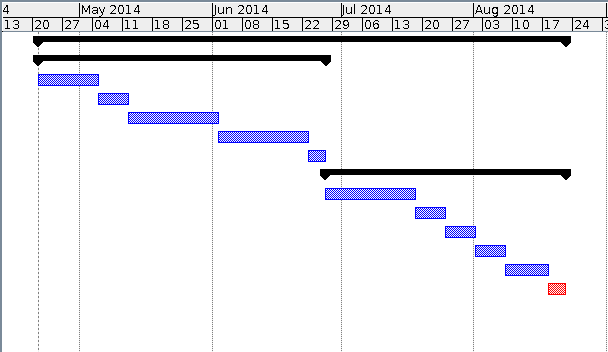
To new contributors of Apache Bloodhound setting up the IDE is pretty straight forward task.
Before setting up the IDE it is required to do the basic environment for Apache Bloodhound by following the installation guide.
After checking out the project code and, creating the virtual environment start PyCharm and follow the following steps to setup the dev environment.
1. Open the project code from Pycharm. From the `File` menu select `Open` and browse through the IDE's file browser to select the base directory that contains the Bloodhound code.
2. In the IDE preferences setup a local interpreter and point it to Python executable in Bloodhound environment.



Local interpreter should point to the Python executable at,
<bloodhound-base-dir>/installer/<environment-name>/bin/python
3. Finally it is required to create a new run configuration in PyCharm.
Add a new `Python` run configuration.

Add the following parameters,
Script: <bloodhound-base-dir>/trac/trac/web/standalone.py
Script Parameters: <bloodhound-base-dir>/installer/bloodhound/environments/main --port=8000
Python Interpreter: Select the added local Python interpreter from the list